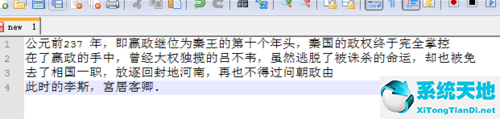
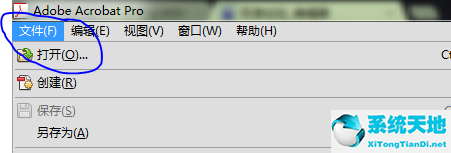
1.首先,运行Adobe Acrobat XI Pro软件,打开要提取文本的pdf文档,如下图所示:
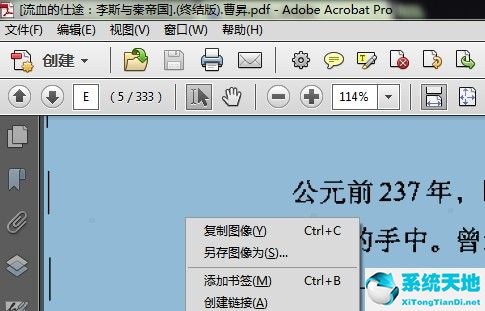
 2,定位到要提取文字的页面,选中,右键看到当前页面是图片,如下图所示:
2,定位到要提取文字的页面,选中,右键看到当前页面是图片,如下图所示:
:  3.在Adobe Acrobat XI Pro软件工具栏的右侧,依次找到工具——识别文本,如下图所示:
3.在Adobe Acrobat XI Pro软件工具栏的右侧,依次找到工具——识别文本,如下图所示:
: 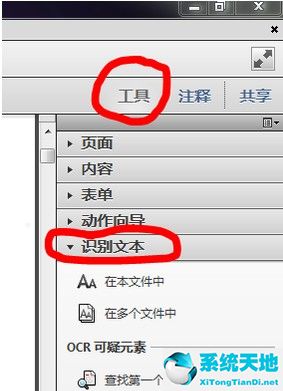 4.单击“在此文件中”打开识别文本的窗口。为了方便,我选择了当前页面,设置中的内容一般不设置。如有必要,可以点击【编辑】按钮修改设置项目,如下图所示:
4.单击“在此文件中”打开识别文本的窗口。为了方便,我选择了当前页面,设置中的内容一般不设置。如有必要,可以点击【编辑】按钮修改设置项目,如下图所示:
: 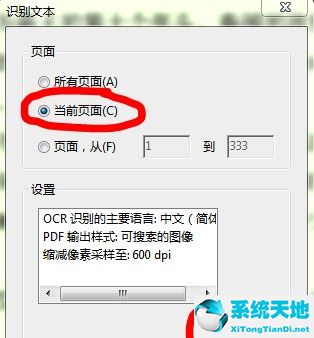 5.点击确定后,软件会自动分析当前页面,然后自动识别其中的文本,如下图所示:
5.点击确定后,软件会自动分析当前页面,然后自动识别其中的文本,如下图所示:
:  6.识别后仍停留在当前页面。不同的是,当你再次右击文本时,可以看到熟悉的副本,也可以选择“将所选项目导出为……”,如下图所示:
6.识别后仍停留在当前页面。不同的是,当你再次右击文本时,可以看到熟悉的副本,也可以选择“将所选项目导出为……”,如下图所示:
:  7.复制后,粘贴到文本文档或需要的地方即可。如下图所示,pdf中的文本被提取出来。
7.复制后,粘贴到文本文档或需要的地方即可。如下图所示,pdf中的文本被提取出来。