半年前,也许你身边只有“技术大牛”在研究大模型,而现在,经历了一波担心被AI替代的打工人,已经学会与之“共存”,并让自己更靠近大模型。而这种靠近的基础,在于企业的“百模大战”已来到一定的层级。
上个月底,多家公司表示旗下的国产大模型产品向全社会开放。而这距离国内较早的大模型产品公开发布还不到半年,大模型发展速度有着迅雷不及掩耳之势。
数据显示,截至2023年7月,中国累计已有130个大模型问世。毫无疑问,参与这场“百模竞赛”的任何一家厂商都不想错失这条看似蕴含无限商机的赛道。
记者认为,竞赛的实质是一场“云计算之争”。而这背后,大模型产品好不好用,还是要看能不能解决实际问题。
在此背景下,各大厂商亦在强调其应用层面的优势,特别是在结合垂直行业的场景中。目前看来,大模型与行业的融合发展已是主要趋势,具体的场景还在逐步探索,一批典型案例则已经发布。
率先发布大模型产品并投入应用,对企业而言的正向效应在于产生“数据飞轮效应”:即更多用户带来更多的数据,以此“反哺”更好的大模型,并无限循环。
值得关注的是,在“百模大战”的大浪淘沙下,剩下的“选手”数量最终可能仅仅是个位数。对于大多数企业而言,如何考虑更早在应用层发力,或是更为值得思考的地方。
率先“卡位”
对普通用户而言,如今要使用一款大模型更多需要考虑的是用哪一款,而不是“一模莫展”。
8月31日凌晨,百度“文心一言”、智谱AI“智谱清言”、商汤科技“商量”、百川智能“百川大模型”等公司纷纷表示,旗下大模型向全社会开放。
从时间的粗线条上来看,从发布大模型到“开闸”,等待并不算久。
百度作为较早公布旗下大模型的公司,3月便发布了“文心一言”;4月,阿里“通义千问”开始邀请测试。此后,各家大模型也陆续“官宣”。
监管方面,我国首个针对生成式人工智能产业的规范性政策《生成式人工智能服务管理暂行办法》已于8月15日正式施行。
图片来源:工信部网站截图
虽然各家大模型在介绍自身的产品特点上都各有侧重,例如强调公司对人工智能长久以来的专注,或强调其在特定语境下的更优表现,再或者表达自身对行业难点的突破......但终归目的只有一个,即在市场中率先“卡位”。
在此背景下,“应用”便成为了理解大模型的关键词。
首先,我们将它作为一个动词看,要想大模型解决实际问题,首先需要投入使用,也就是“如何应用”。
比如,9月7日发布的腾讯混元大模型,已经接入腾讯50多个业务,包括腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ浏览器等。
“我们研发大模型的目标不是在评测上获得高分,而是将技术应用到实际场景中。腾讯将全面拥抱大模型。”腾讯集团副总裁蒋杰说道。

图片来源:腾讯全球数字生态大会公众号
再者,我们也可以把应用看做一个名词。面对形形色色的需求,大模型需要找到合适的路径或载体。类比安卓或iOS这样的操作系统,未来大模型的生态或许也将建立在无数的应用之上。
此前,我们在大模型“混战”一文里有提到,如今的IT技术栈分为四层,芯片层、框架层、模型层和应用层。今天的ChatGPT、文心一言等属于模型层,AI时代的原生应用都会基于大模型来开发。
业内一种观点认为,如果说ChatGPT的出现是人工智能的“iPhone时刻”,GPT4插件功能的发布则让人看到App Store的出现。基于此,称呼大模型为“轮子”也好,“底座”也好,无外乎不在突出其基石功能。
“模型本身是不直接产生价值的,基于基础大模型开发出来的应用才是模型存在的意义,对于创业者来说,卷大模型没有意义,卷应用机会更大。”9月5日,在2023百度云智大会上,百度创始人、董事长兼首席执行官李彦宏如是说。

图片来源:百度公众号
再进一步看,这背后更是一场“云计算之争”。
即便是采用开源大模型,算力便是一头不可绕开的“拦路虎”。此外,开源大模型的算法和数据亦有优化空间。因此,除了推出自研大模型之外,主要的云厂商在大模型服务方面亦在频繁发力,MaaS成为新的商业模式。
如何“落地”
生活、能源、金融、医疗、城市治理、科学研究……与更早之前火爆的元宇宙概念不同,伴随着各种“型号”的大模型,典型的应用场景正来到我们身边。
在公众的视野当中,采用图像大模型打造的产品是较早挣到钱的一批。
在这其中,闭源的Midjourney无疑是其中的佼佼者。不少报道都提及这家创立于2021年8月的公司,只有11名全职员工,不到一年便实现1000万用户和1亿美元营收的壮举。
据报道,目前Midjourney团队成员已经扩大至40名,这些员工今年有望为Midjourney创造2亿美元的营收。
另一方面,采用开源的Stable Diffusion,其部分产品也已实现商业闭环。典型的如7月推出的妙鸭相机,一段时间内几乎横扫社交媒体,不少用户都纷纷上传自己不同风格的“数字分身”。
据第一财经报道,妙鸭相机实际用到的技术并不复杂,应该是搭配了LoRA插件的Stable Diffusion开源模型。
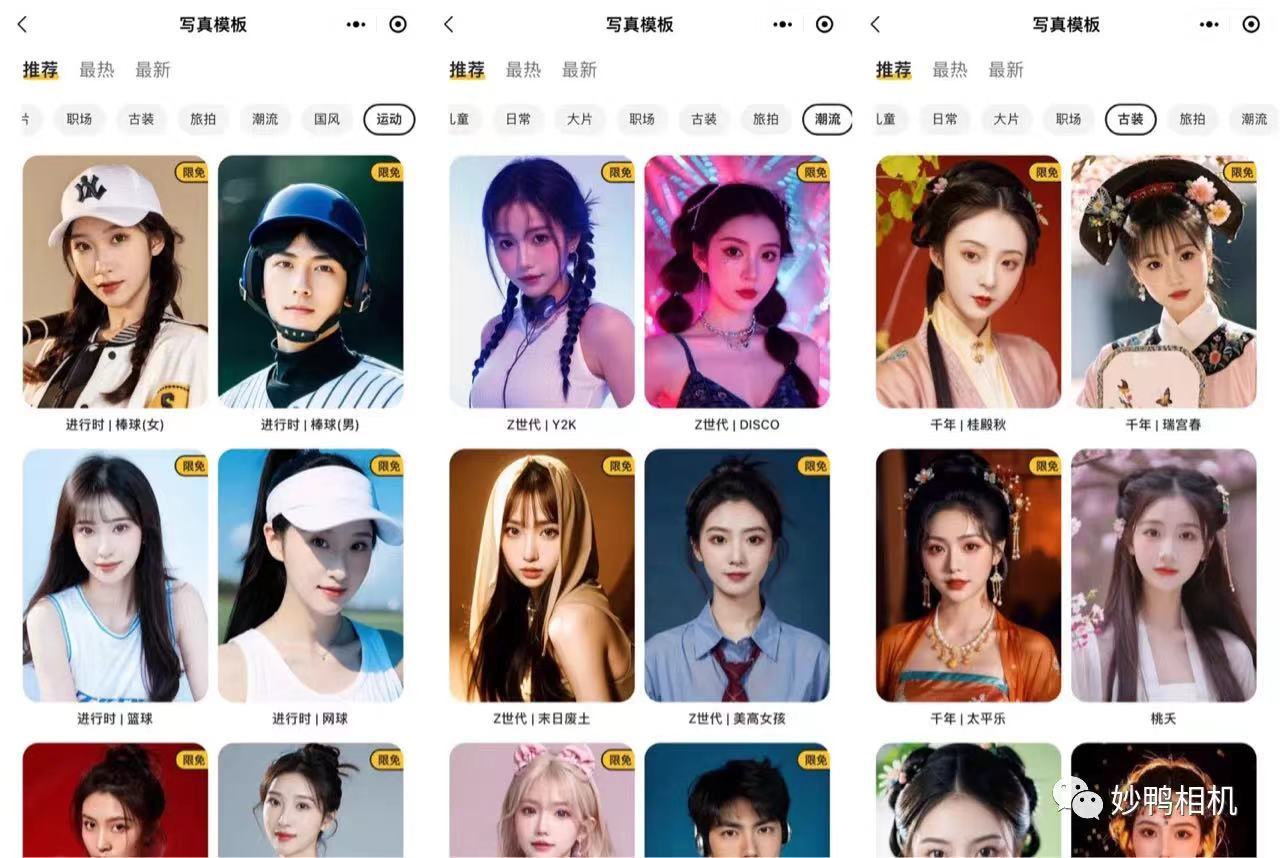
图片来源:妙鸭相机公众号
在面向普通用户的热闹之余,企业的自有场景也成为重点关注对象。
实际上,迅速浏览一遍各大云厂商的打法,这一“玄机”便不是秘密。换句话说,消费者可以通过语言类或视觉类产品来“玩”大模型,企业则需要大模型及其产品以实现“降本提质增效”。
这方面已有一批典型案例。在北京发布首批10个行业大模型典型应用案例中,基于电力行业NLP大模型的设备运检知识助手示范应用、数字中医大模型示范应用、面向建筑领域多模态行业大模型示范应用等案例,都展现出大模型与行业之间的融合可能性。

图片来源:北京国际科技创新中心公众号
实际上,在目前来看,大模型应用场景显露的商机只可看作“小荷才露尖尖角”。
在上周才举行的2023 INCLUSION·外滩大会上,专家普遍认为大模型产品的产业红利才刚刚开始。
麦肯锡中国区主席、全球资深董事合伙人倪以理在现场预测,生成式AI的技术风暴有望开启一场关系到未来8-10年的新一轮技术和产业变革。“AI对全球经济的潜在收益将达到25万亿美元,是当前所有企业最重要的赛道之一,但这个时代刚刚开始。”
数据飞轮
什么是“数据飞轮效应”?GPT4给出的精简版回答是:
数据飞轮效应是一个概念,描述了数据、产品和用户之间的正向反馈循环。初始阶段,公司通过服务吸引用户,这些用户产生数据。随着数据的积累,公司可以分析这些数据,优化其服务以更好地满足用户需求。优化后的服务吸引更多用户,从而产生更多数据。这形成了一个正向循环:更多的用户带来更多的数据,而更多的数据又帮助公司进一步优化服务。
这也能解释为什么包括GPT4在内的几乎所有语言类大模型,都会在回复的同时提供反馈的按钮。
宏观层面上来讲,在全世界范围内的大模型大浪潮中,数据或将成为国产大模型的优势。这一现象从移动互联网时代产品上便可窥探一二。
据硅基研究室,国内大模型应用场景之所以与国外产生差异,本质上是在算力、算法不占优势的背景下,加速“数据-模型-数据”的发展飞轮成型。也就是说,经过大量用户使用后,这个飞轮得以不断“转”起来,大模型的不完美之处才有机会得以被弥补。
因此,对于大模型而言,高质量数据的重要性不言而喻。但这又将不可避免地涉及到隐私问题,以至于衍生到数据安全方面的问题。一个经常会被用使用的案例是医疗行业,不仅由于其专业性强,而且还在于其数据尤为敏感,比如会涉及到患者病情等大量个人信息。
回归到大模型本身,要产生数据飞轮效应,意味着要有用户使用。这也一定程度上回答了为何国内大模型要争先上马,打响字面意义上的“百模大战”。
据中国经济网从赛迪方面获得的一份数据显示,今年1-7月国内共发布了64个大模型。截至2023年7月,中国累计已经有130个大模型问世。
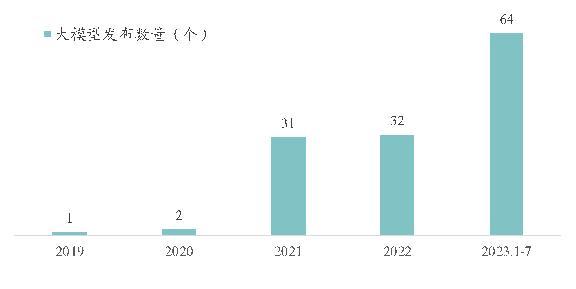
图片来源:中国经济网 数据来源:赛迪顾问《IT 2023》
硝烟弥漫之际,正如如今的手机操作系统生态,业内人士在展望未来的大模型生态时也预计其数量将是“几个”。
在接受腾讯科技的采访时,智源研究院院长黄铁军表示,大模型是AI时代的基础设施,未来全球大模型的生态不会超过三个,而身处中间层的企业可以早点开始在应用层找机会。