9月13日消息,小米自研声音识别算法在音频标记(Audio Tagging)任务中取得重要进展。以公开数据集AudioSet-2M的音频数据作为训练集的音频标记模型,首次突破50 mAP的分数,此项突破标志着小米声音识别算法已在国际上性能排名第一。

据了解,Google将AudioSet数据集分为三个子集,前两个子集用于训练,被合并称为“AudioSet-2M”。正是在这个合并后的训练集中,小米的声音识别算法模型首次在业界突破了50 mAP,刷新了音频标记技术指标,成为截至目前性能最好的模型。
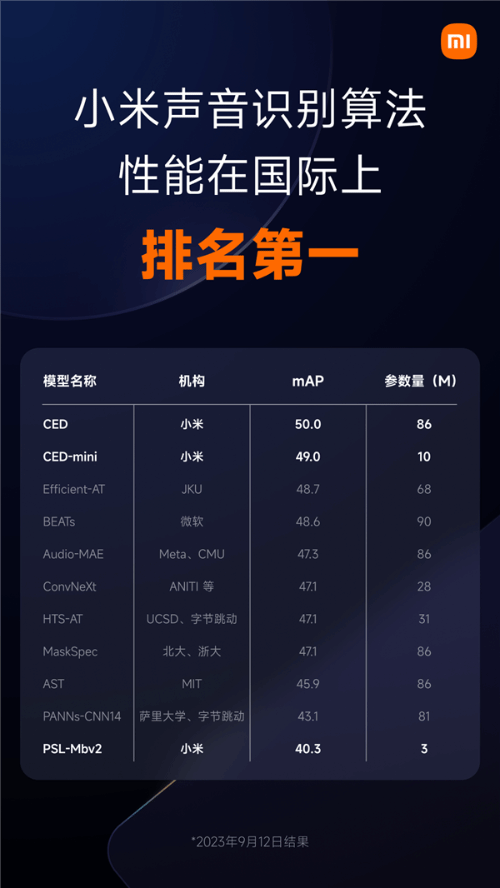
此外,小米还发布了一个Mini版模型,适合资源受限的场景。该模型的参数量被压缩到了原模型的约九分之一,远小于其他机构的模型,但性能却优于其他所有机构。